
Pernah mendengar tentang Amazon Go? Kalau belum, silakan tonton video ini. Di situ kita bisa melihat visi Amazon terhadap pasar swalayan masa depan, di mana kita bisa berbelanja kebutuhan sehari-hari tanpa perlu mengantre untuk membayar.
Sejauh ini sudah ada delapan Amazon Go yang dibuka di tiga kota di Amerika Serikat, dan di semua toko itu pengunjung bisa melihat deretan kamera yang terpasang di bagian langit-langit. Kamera-kamera itulah yang bertugas mengenali setiap produk yang konsumen ambil dari rak.
Kalau melihat Amazon sebagai perusahaan dengan aset yang begitu besar, sulit rasanya bagi jaringan toko ritel lain untuk bisa bersaing, setidaknya dalam waktu dekat ini. Namun itu tidak mencegah sebuah startup bernama Caper untuk menawarkan alternatif yang tak kalah menarik.

Produk mereka adalah sebuah troli belanja pintar sekaligus mesin kasir otomatis. Bentuknya sepintas seperti troli belanja biasa, akan tetapi Caper telah melengkapinya dengan tiga kamera berteknologi image recognition beserta sensor berat, sehingga sistem bisa langsung mengenali produk yang konsumen cemplungkan ke dalam troli.
Selesai berbelanja, konsumen tidak perlu mengantre di kasir. Persis di depan dorongannya, ada mesin EDC untuk menggesekkan kartu kredit maupun scanner untuk membayar via Apple Pay atau Google Play. Skenario akhirnya mirip seperti Amazon Go: konsumen dapat langsung meninggalkan toko selagi membawa belanjaannya.
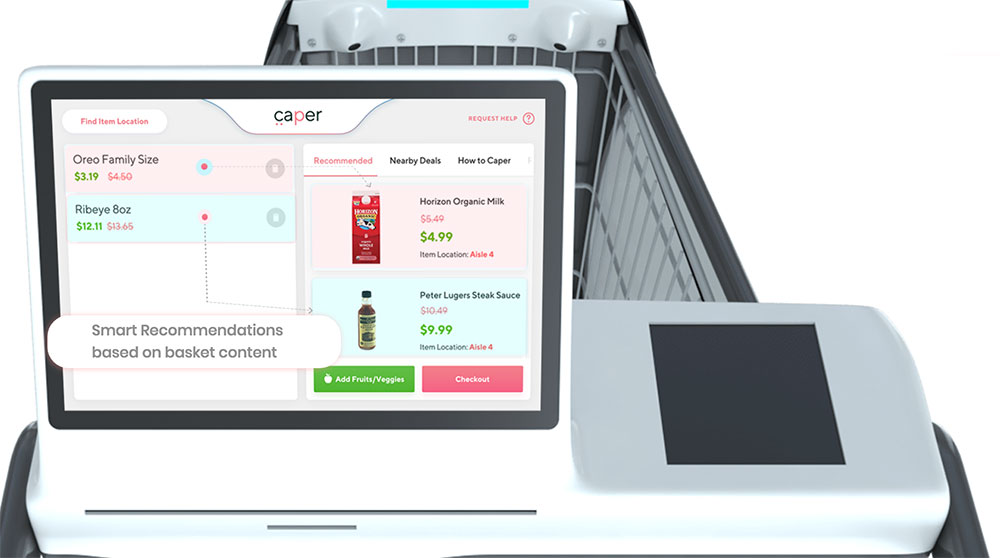
Kendalanya untuk sekarang, teknologi yang Caper kembangkan masih belum benar-benar matang, sehingga terkadang konsumen perlu menggunakan barcode scanner yang terdapat pada troli untuk mendeteksi produk yang dibelinya.
Sejauh ini memang belum banyak toko-toko yang menggunakan teknologi Caper. Trolinya sendiri dijual tidak jauh lebih mahal dari troli belanja standar, akan tetapi pihak toko juga harus membayar biaya subscription untuk bisa menggunakan layanan Caper sepenuhnya.
Sumber: TechCrunch.


